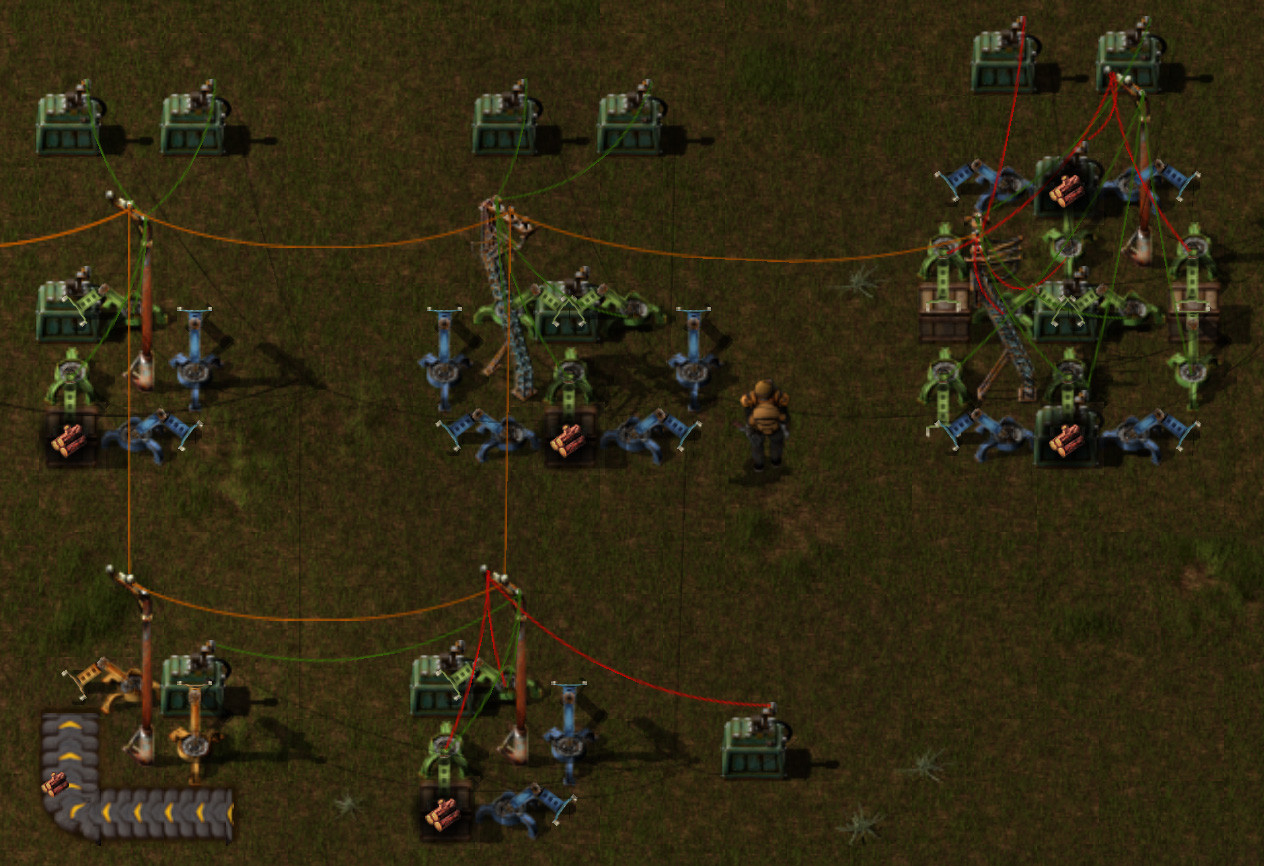
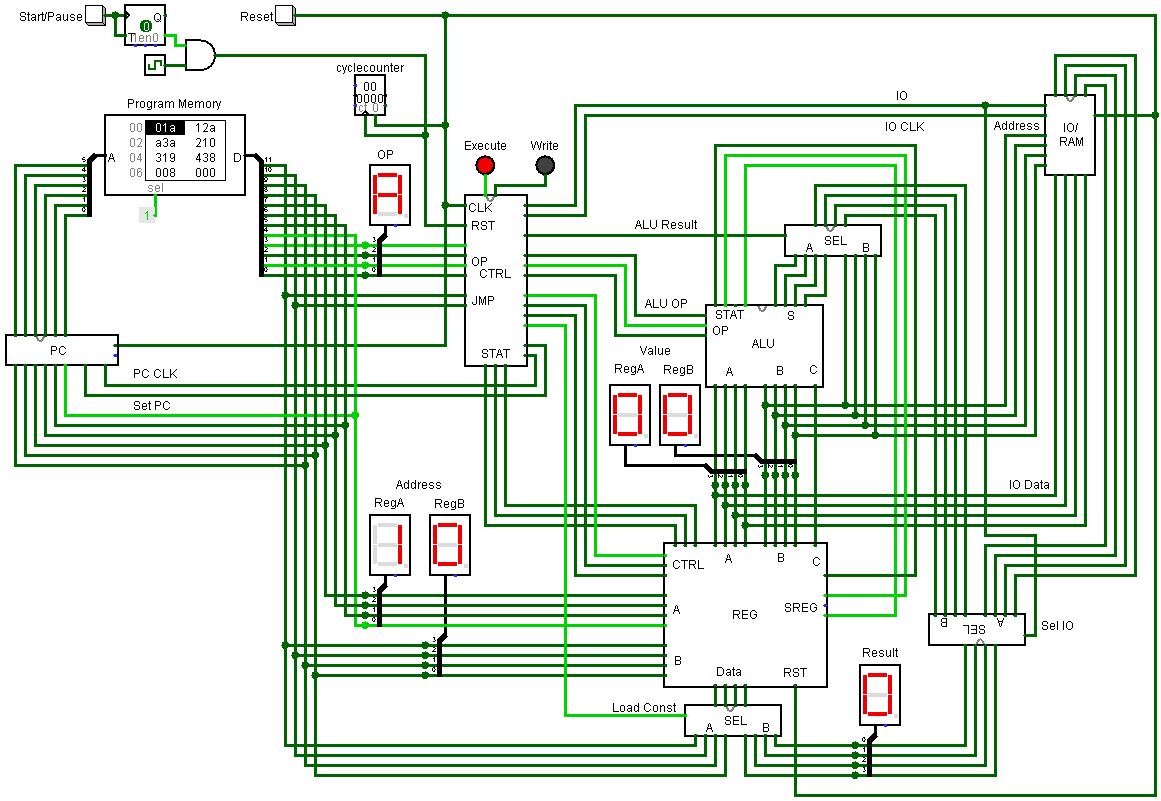
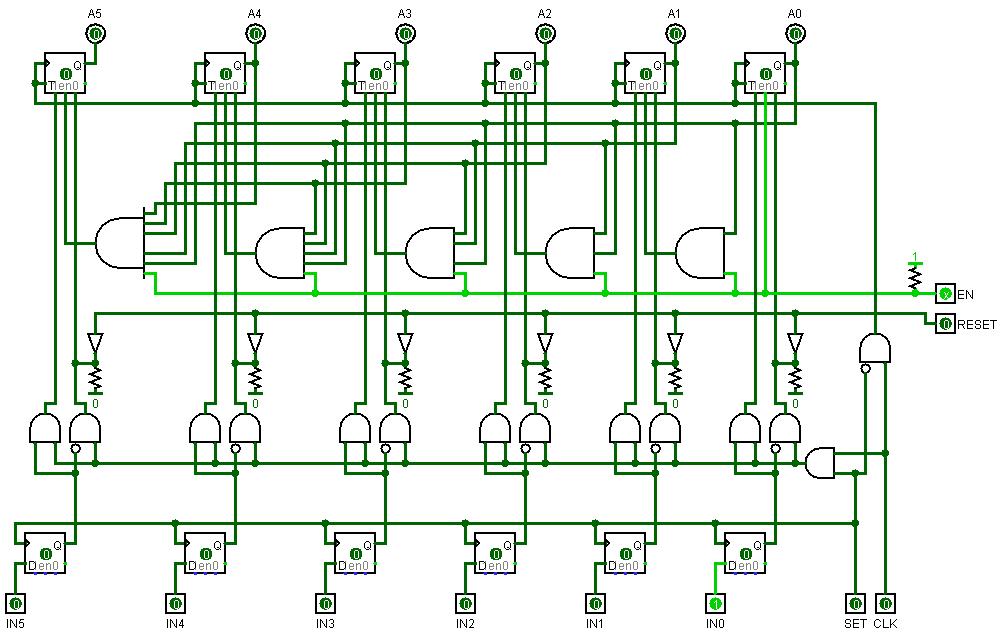
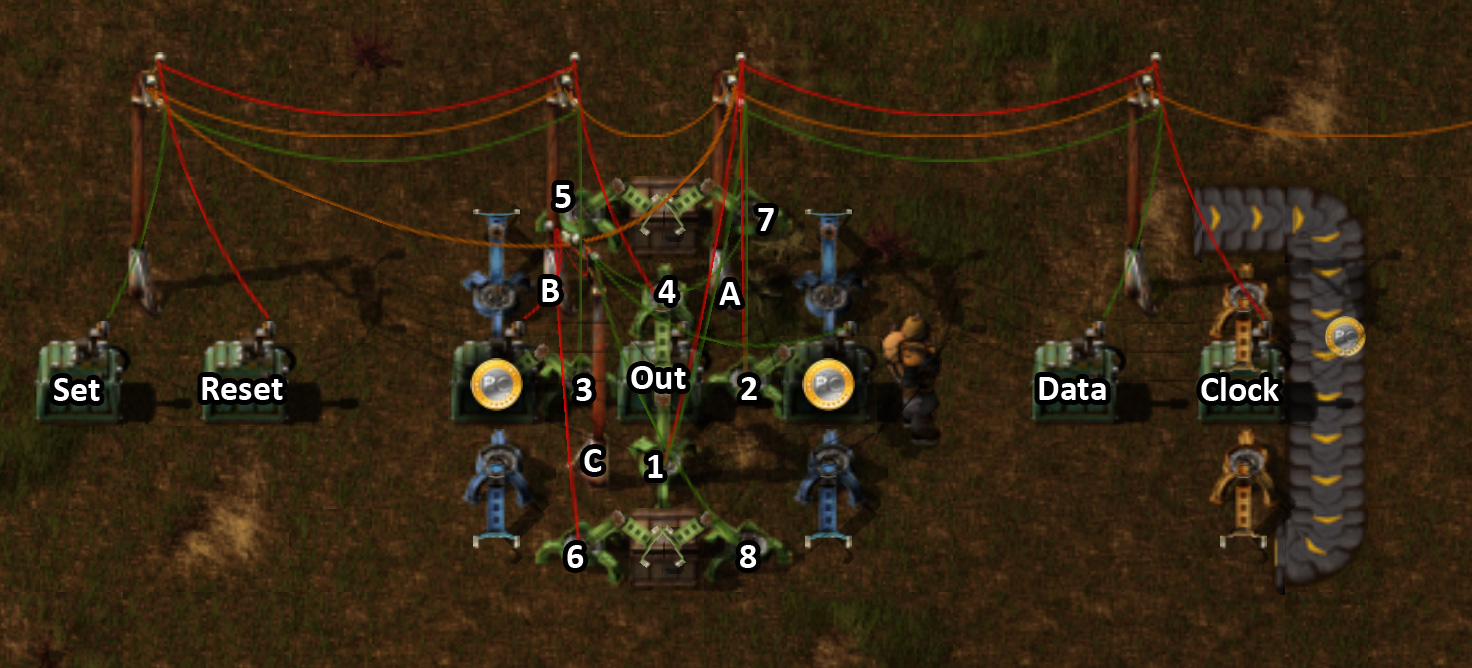
zaubara, I tried to look at your 4-Bit-CPU.zip file. It downloads as a 67,466 byte file, but when I try to unzip it:
C:\temp\factorio>unzip 4-Bit-CPU.zip
Archive: 4-Bit-CPU.zip
End-of-central-directory signature not found. Either this file is not
a zipfile, or it constitutes one disk of a multi-part archive. In the
latter case the central directory and zipfile comment will be found on
the last disk(s) of this archive.
unzip: cannot find zipfile directory in 4-Bit-CPU.zip,
and cannot find 4-Bit-CPU.zip.zip, period.
I tried InfoZip (above), windows explorer and 7-Zip and they all say the zip file is invalid.
zaubara wrote:do you have a suggestion what operations could fit into this?
Well, you asked for it.

Since I can't look at the details in 4-Bit-CPU.zip, I'm just going by the instruction list you gave earlier:
zaubara wrote:ADD, SUB, AND, OR, NOT, XOR, SHL, SHR, JMP, JNZ, JLS, CMP, LDI, MOV, IN and OUT
If NOT, SHL, SHR use the same register as both source and destination (as is common in most actual machine languages), then those instructions would be candidates for the one-register format.
I don't think your current datapath supports it, but I see you have LDI and MOV as separate instructions, and don't have ADDI, SUBI, ANDI, ORI, XORI or CMPI. Considering how much instruction space you have available it would make sense to generalize ADD, SUB, AND, OR, XOR, CMP and LDI/MOV to be able to have the second source operand be either a register or an immediate, and then LDI is just the 'I' variant of MOV. Just use one of the opcode bits to select between use-immediate and read-reg-B. That would also allow coding "ADDI r, 1" and "SUBI r, 1" in a single instruction, which would eliminate any need for one set of commonly included single-register instructions: INC, DEC
Argh - I just tried it and having 'I' variants of everything
almost fits, but not quite. I think it would be worth considering expanding the instruction size from 12 bits to 13 bits because even though that's an 8% increase in instruction size, it would likely decrease a program's size by more than 8%. Here's my attempt at fitting into 12 bits:
Code: Select all
xxx0 (xxx != 0): two register; xxx1 (xxx != 0): one register + one immediate
0010 ADD 0011 ADDI
0100 SUB 0101 SUBI
0110 AND 0111 ANDI
1000 OR 1001 ORI
1010 XOR 1011 XORI
1100 CMP 1101 CMPI
1110 MOV 1111 MOVI
load/store (IN/OUT):
0000 IN 1000 OUT
sorry, no opcode space left for:
NOT, SHL, SHR
JMP, JNZ, JLS
With 13 bits there's plenty of space (even with 'I' variants of IN/OUT as well so you can read/write absolute IO/RAM addresses without having to preload the address in a register):
Code: Select all
xxxx0 (xxxx <= 1000): two register; xxxx1 (xxxx <= 1000): one register + one immediate
00000 IN 00001 INI
00010 OUT 00011 OUTI
00100 ADD 00101 ADDI
00110 SUB 00111 SUBI
01000 CMP 01001 CMPI
01010 AND 01011 ANDI
01100 OR 01101 ORI
01110 XOR 01111 XORI
10000 MOV 10001 MOVI
10010 unused/available
...
11101 unused/available
11110 one-register instructions (NOT, SHL, SHR; up to 4 additional opcode bits used for operation type)
11111 branches (JMP, JNZ, JLS; 2 additional opcode bits used for branch type)
If I were creating a real instruction set (especially a 4-bit one!), there's some more instructions that would be needed for practical use ("practical use" in factorio definitely including the ability to add, subtract, compare and shift values greater than 4 bits):
Code: Select all
10100 ADDC 10101 ADDCI (add with carry)
10110 SUBC 10111 SUBCI (subtract with carry/borrow)
11000 CMPC 11001 CMPCI (compare with carry/Z-flag; see CPC instruction in Atmel AVR instruction set if you've never seen something like this - a lot of architectures have a big gaping whole where this instruction belongs!)
one-register instructions: ROR, ROL (rotate right/left though carry)
The move to 13 bits would also let you have a full set of conditional branches rather than just JNZ/JLS. (That can also save program space by not needing to use the "conditional branch around unconditional branch" idiom to synthesize the branch you really want.)
It's also common to have an ASR (arithmetic shift right) instruction for shifting signed data. (I'm assuming your current SHR instruction shifts 0s in rather than duplicating the sign bit.)
A lot of instruction sets also have some way to read/write flags registers (to/from a register and/or to/from memory). For
most code, though, that's probably more "nice to have" than "essential".
One big thing that's really missing from your instruction set is an ability to do proper subroutines. Currently you could use one register as a stack pointer, and by manipulating it with ADD/SUB and using it as an address you could push and pop data. You could even store a return address (as two nibbles) by doing two 'LDI's with the two parts of the return address and then using 'OUT's to push them to the stack. You could also pop the return address into two registers. So far, so good (if a bit verbose in terms of instruction words used). But then there's one last missing piece to pull it off, and that is that you don't have an indexed jump instruction (i.e., an instruction that does "jump to address stored in register(s)"). So even with the return address sitting in two registers (two because addresses are 6 bits and registers are only 4 bits), there's no way to jump back to the return address. (Adding that feature would also fix the lack of ability to do jump tables, though your program size is so small jump tables are probably something you'd never use anyways, so really it's making subroutines work that is the issue here.)
In super-small architectures (with very little program memory), subroutines are your friend. (Some might say they are your Lord and Savior Jesus Christ because they're that important to getting programs to fit.) There is a work-around, but it's a bit ugly. And that is to have every subroutine know about all of its callers. Then for each subroutine enumerate the callers 0..N-1. Instead of pushing/popping an address you push/pop that index. Then instead of doing a normal kind of return-from-subroutine, you end each subroutine with a bunch of CMPs (comparing the popped index) alternating with conditional branches to the (hard-coded) return addresses. (You could teach this idiom to your assembler and have it do this automagically -- then have JSR and RET pseudo-instructions.) Of course, between this and not having proper PUSH/POP instructions, your overhead (not just in timing but in amount of program space consumed) for subroutines and subroutine calls is going to be pretty high. (Personally I am somewhat fond of the 6809 instruction set where a 2-byte POP instruction can pop any arbitrary combination of Flags, A, B, X, Y, and U registers, as well as the PC so you don't even need a separate RETurn instruction.)
If this were a real instruction set I would also complain loudly about the lack of any register+immediate_offset addressing. But I can understand that that would be quite a bit of work to add in this case because it requires 2 registers and an offset which would mean it would have to be a multi-program-word instruction which would really complicate your instruction decoding and control scheme. If, kind of like how I believe the MIPS assembler works, you dedicate one register as "assembler-owned/controlled temporary register", you could make your assembler emulate the addressing mode, though it will take 3 instruction words instead of just 2: MOV reg to temp, ADD offset to temp, then do the IN/OUT instruction using temp as the address
Push/pop instructions are also really good candidates for being assembler pseudo instructions. Just have one register that is considered "the stack pointer". Then the assembler accepts instructions like "push r1, r7, r10" and outputs machine code: subi sp, 1; out sp, r1; subi sp, 1; out sp, r7; subi sp, 1; out sp, r10
Auto-increment/auto-decrement addressing is another good candidate for being pseudo instructions -- the assembler accepts "out r8++, r4; out r8++, r5" and outputs "out r8, r4; addi r8, 1; out r8, r5; addi r8, 1"
Of course, you can get carried away with that. I mean, once you start introducing math operations with absolute memory addressing as a pseudo-instruction (e.g., assembler accepts "add foo, 1" and outputs "ini temp, addressof(foo); addi temp, 1; outi addressof(foo), temp") you've almost got a C compiler -- may as well make it just accept "foo++" as a statement.

Motorola had an interesting concept which I don't know if you're interested in, but since you create different CPUs maybe you are... the concept was basically "(somewhat) portable assembly language". They used this in the 68xx line of microprocessors and microcontrollers. At a machine code level, they had different instruction sets and encodings (some much more capable than others), but (in theory, I didn't try this myself, even though I have both 6809 and 6811 experience - also 6803 but I only programmed that in machine code, never had an assembler) you could write assembly code that worked on all of them. On "lesser architectures" that assembly code would translate to a lot more machine instructions, but it would still work.
zaubara wrote:"6 cells for the addressing"
zaubara wrote:Do you have some tricks or other interesting solutions you want to share?
Have? Yes. Want to share... um, er, I guess.

(If I give away my secrets, how will I build the super-duperest 'puter?)
For example, it doesn't take 6 cells to do addressing. As long as you have the inserter stack bonuses, you can move up to 5 items at a time. You can do some extra work up-front on the address before "transmitting" it up to the address decoders - have one cell moving 4 items, one moving 2 and one moving 1. (Obviously anything greater than 1 can't involve belts, and the obvious choice is box-to-box.) You can then "wire-add" those together (just tie them together with a single red/green wire and let factorio add up the item counts: 0..7). That lets you code 3 bits into one wire. But you need 6 bits? Fine, do it twice, use two different materials, and now you can put 6 bits into one wire. At each program word just use 2 cells, one for each group of 3 bits. (Just set the logic condition to be "wood=0" .. "wood=7" to decode the first 3 bits in the first cell, and "iron_ore=0"..."iron_ore=7" for the other 3 bits in the second cell.) Have I blown your mind yet? No? Then how about doing it in one cell. One cell requires using both red and green wires (3 bits each), and then you can set both conditions on the one cell. But where's the clock coming from then? Logistics network!

The above trick can also be used when MUXing different result buses together.
You can do a similar thing with the program words themselves, storing 2 bits per cell. When moving items into "read position", move up to 3 items at once. (Unfortunately I haven't figured out how to do a similar trick with RAM yet. This trick might not be much of a win if you have enough '0' bits you could have just left out anyways.)
(OK, I really need to test these ideas. Maybe I'm just full of crap. I started a new game with 11.15 with resources all set to high and biters set to low because I think that would be a good environment for building a really big computer, but I still haven't got to the computer building/testing part yet -- this game takes too many damn hours!)
***
Anyone working on a computer based on 0.11.x may want to hurry up, as 0.12 may make it "obsolete". (It might still work, but would not be very good compared to what can be made in 0.12 -- but then again, that may be a good excuse to make
another computer!) From
here:
To be able to manipulate the signal better, we will have a new piece called combinator. This piece will allow to do certain manipulations with the signal, like conditional statements or multiplications (simple linear combinations).
Also, from that same post is news that 0.12 will have 'stdout' covered:
light, condition can be specified, can be colored depending the singal
EDIT: zaubara, if you have the XORI instruction, then you don't need the NOT instruction -- you can just do "XORI reg, 0x0f" rather than "NOT reg".